前言
很多时候,外网打点,资产就那么点,社工钓鱼又钓不进去,那么怎么办呢?这时候只能传统艺能爆破来解决问题了。
但是,抛开IP先不说,现在登录多多少少都会有加上验证码用于防止爆破,但是这种东西肯定不能阻挡我们的脚步。所以最简单的办法就是整个自动用于验证码识别的玩意。下至OCR上至机器学习乃至购买云打码。因为我们穷云服务肯定整不起,OCR识别率又堪忧,所以最简单的办法就是去github整一个。
说明
本篇就是一个踩坑文章(然而作者的项目写的非常不错,并没有遇到什么坑hhhh),用于记录,没有什么技术含量。我才不会说我是实在想不出写什么东西才水一篇文章的呢,哼~
最近快毕业了,什么毕业论文啊个人音乐会啊毕业音乐会啊专场啊以及最讨厌的查缺补漏(指舞蹈重修)。虽然说这些事并不麻烦,但是确实都是事,每天就这么磨洋工一点一点的磨磨唧唧但是也确实在解决。导致我用一般只日站,很少沉下心来写这些完整的学习报告了。虽然说日站过程中也会遇到一些新鲜的东西,例如这次就遇到很多K8s啊,云安全啊但是这些并没有完整的,全面的研究,导致博客一直不知道写啥。所以就搞了水了一些实践报告,网络上也有他人的实践记录。但是我会尽量把所有的坑给列出来。
话不多说,开整。
开整
既然不是自己写项目而是用东西,那肯定是怎么简单怎么来,去年还是前年我用过
https://github.com/nickliqian/cnn_captcha 项目跑过训练,效果确实不错,然而截至至今(2022年4月22日),该项目大部分依赖已经爆炸,遂直接放弃
最后还是选择使用captcha_trainer 项目来使用。凑巧的是,作者也在FreeBuf上发布过文章,详细说明了如何使用该项目,详情可以看这里
然而作者对于Linux部分写的很详细,对于Windows部分却是一笔带过。刚好我用的是windows,就顺带记录了。
话不多说,开整。
安装CUDA
首先是下载项目,直接git clone就行,重点是第二部
目前为止,如果你是使用CPU训练,那么可以跳过下面这一步骤,因为源码已经加入代码默认支持CPU了,不需要进行过多操作,如果是GPU,就需要安装CUDA和CuDnn。直接根据文章,从官网下载
- https://developer.nvidia.com/cuda-10.0-download-archive 下载CUDA
- https://developer.nvidia.com/cudnn 下载CUDNN
下载完以上上面,首先得先安装CUDA,安装完毕之后,解压CUDNN,然后根据cudnn/install-guide,
找到CUDA安装目录,这里假设CUDA安装目录是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\
复制 bin\cudnn*.dll 到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vx.x\bin.复制 include\cudnn*.h 到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vx.x\include.复制 lib\x64\cudnn*.lib 到 C:Program FilesNVIDIA GPU Computing ToolkitCUDAvx.xlibx64.`
之后把CUDA目录,也就是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\添加到PATH环境变量中,注意不带bin。
然后还得安装zlib运行库,不然会出现Could not locate zlibwapi.dll. Please make sure it is in your library path,也是根据上面的文档,从ZLIB DLL下载压缩包,把里面的各种.lib文件和.dll文件全部一股脑丢PATH下,你可以选择创建一个PATH,反正我是全部直接丢到system32下。通过以上这些,CUDA就安装好了
安装本体
我用的是python3.10.3,实际上是可以直接使用的
回到我们项目文件,我们可以使用作者的venv,也可以直接莽上去,开干。我的建议是用一些pyvenv。
直接python -m pip install pyvenv。然后记得使用cmd,执行cd venv/ && Scripts/active.bat,看到前面出现(venv)就说明环境载入成功了。
然后就是修改requirements.txt文件,把最后的tf-nightly-gpu==2.8.0.dev20211021改成tf-nightly-gpu即可。
如果是用CPU渲染,就直接安装tf-nightly就行。
记得使用pip安装的时候,务必使用代理,可以用自带--proxy命令指明socks5代理或者像我一样用Proxifier直接把pipy.org加入代理规则里。
安装完requirements.txt之后,直接运行python app.py,还会出现一些依赖错误比如pillow啊这些的,剩下的基本就是缺啥装啥就好了。
之后运行python app.py。
就能打开界面。
训练
对于开源项目来说,我们可以直接把源码部分扒出来,根据作者的要求,只需要生成格式为 验证码原始内容_md5.png 类型的图片放置到目录下就行。我们直接随手谷歌找了一个python验证码生成的代码生成一些数据试试。
import os
import random
import io
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
import hashlib
def random_color():
c1 = random.randint(0, 255)
c2 = random.randint(0, 255)
c3 = random.randint(0, 255)
return c1, c2, c3
def generate_picture(width=120, height=35):
image = Image.new('RGB', (width, height), random_color())
return image
def random_str():
random_num = str(random.randint(0, 9))
random_low_alpha = chr(random.randint(97, 122))
random_char = random.choice([random_num, random_low_alpha])
return random_char
def draw_str(count, image, font_size):
draw = ImageDraw.Draw(image)
# 获取一个font字体对象参数是ttf的字体文件的目录,以及字体的大小
font_file = os.path.join('andale-mono.ttf')
font = ImageFont.truetype(font_file, size=font_size)
temp = []
for i in range(count):
random_char = random_str()
draw.text((10+i*30, -2), random_char, random_color(),font=font)
temp.append(random_char)
valid_str = "".join(temp) # 验证码
return valid_str, image
def noise(image, width=120, height=35, line_count=3, point_count=20):
draw = ImageDraw.Draw(image)
for i in range(line_count):
x1 = random.randint(0, width)
x2 = random.randint(0, width)
y1 = random.randint(0, height)
y2 = random.randint(0, height)
draw.line((x1, y1, x2, y2), fill=random_color())
# 画点
for i in range(point_count):
draw.point([random.randint(0, width), random.randint(0, height)], fill=random_color())
x = random.randint(0, width)
y = random.randint(0, height)
draw.arc((x, y, x + 4, y + 4), 0, 90, fill=random_color())
return image
def valid_code():
image = generate_picture()
valid_str, image = draw_str(4, image, 35)
image = noise(image)
m = hashlib.md5()
with io.BytesIO() as memf:
image.save(memf, 'PNG')
data = memf.getvalue()
m.update(data)
md5 = m.hexdigest()
f = open("demo/trains/{}_{}.png".format(valid_str,md5),"wb")
image.save(f, 'png')
f.close()
return valid_str,md5
if __name__ == '__main__':
for i in range(1,60000):
valid_code()在项目目录下创建一个demo/trains目录,并运行该代码,就会在该目录生成59999张验证码。之后我们在app.py里的project区随便新建一个项目名
之后点击Trining Path里的Browse选项,把我们刚刚生成的目录添加进去
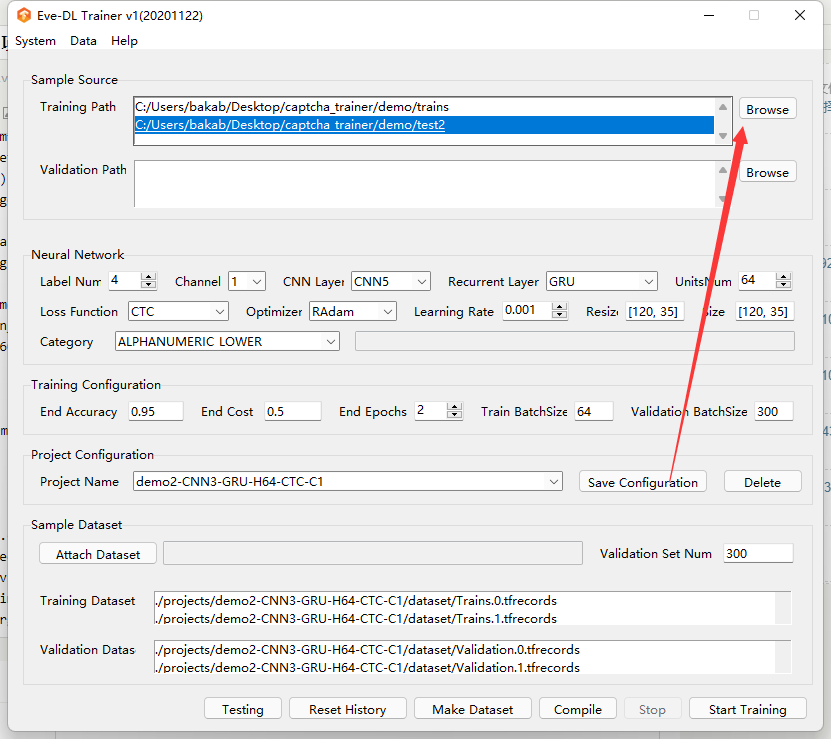
之后点击底下的Make Dataset把我们生成的打包成TFRecords文件,然后点Start Tringing就可以开始训练了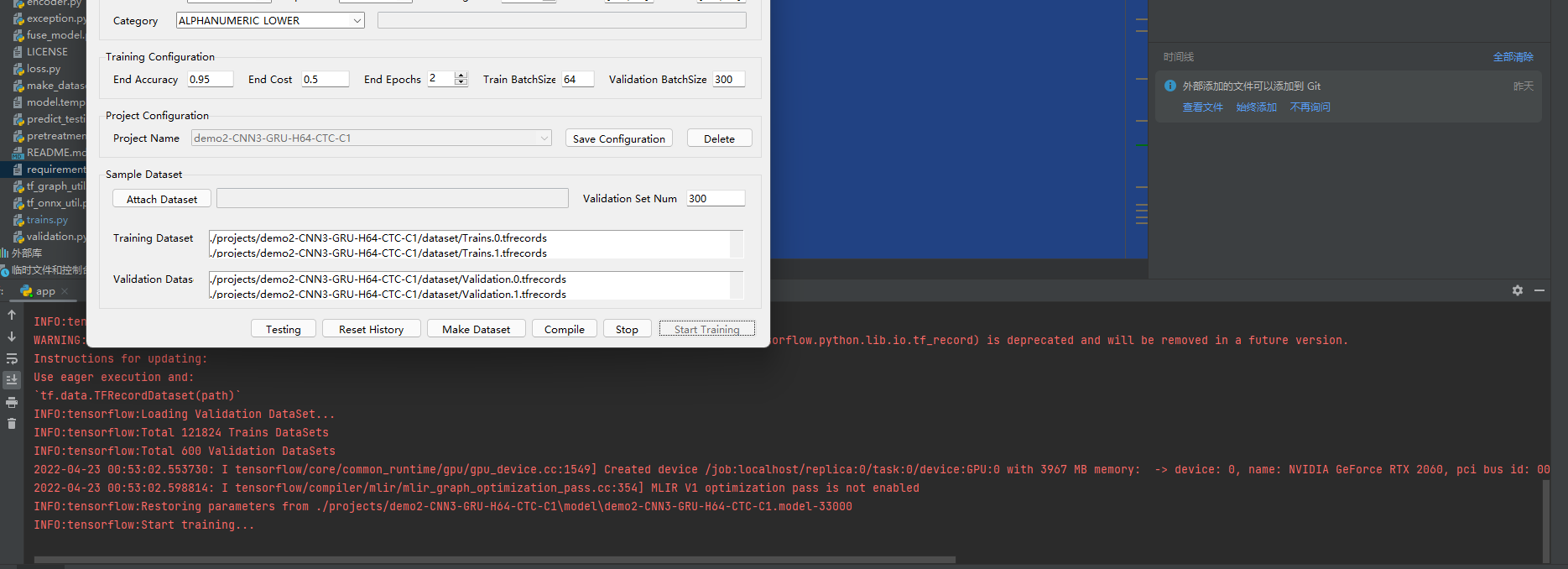
如果你的显卡好的话,大概几分钟,这6W张图片就能训练完成。效率还是很快的
之后我们点击Test,会让我们选择文件夹,我们就可以用这个来验证识别率辣。保险起见我们用上面的代码生成一个Test2文件夹来存放新的。
然后运行Test,测试下效果。
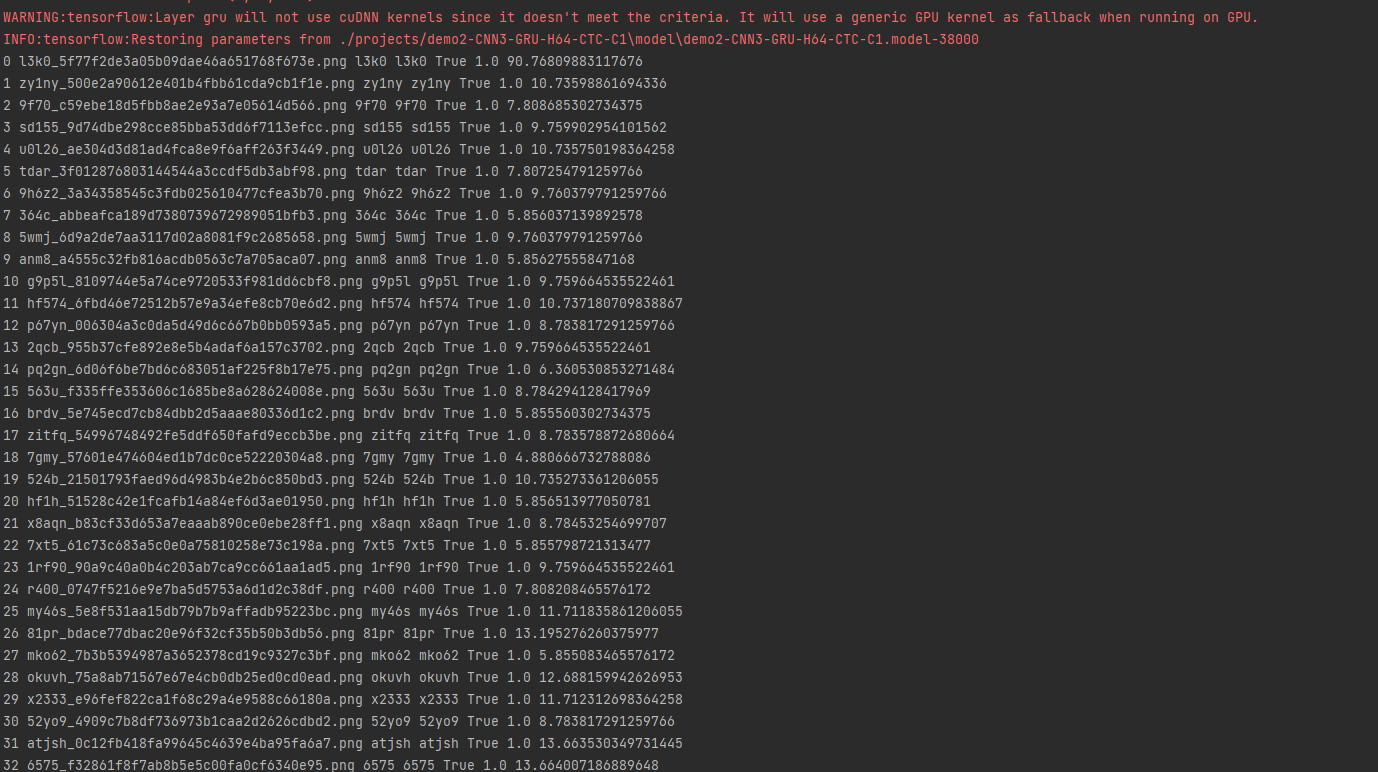
可以看出来效果还是挺不错的,对于开源项目使用这个方法,就可以快速训练出匹配的模型,成功率还是非常高的。重点是非常的方便快捷
部署以及武器化
作者自带了一个框架captcha_platform,我们可以直接使用该项目。
用作部署于服务器的话,没必要上GPU,CPU跑模型就行,所以可以跳过上面的安装CUDA和cuDNN的操作。
安装方法也很简单,直接运行python -m pip install -r requirements.txt就行。
注意,如果是本机部署(和上一个项目同一台机器)的推荐删除requirements.txt里的tf-nightly项,避免环境造成冲突。
之后把我们在captcha_trainer里生成的模型,一般目录是Project/模型名称/out,里的两个文件夹,复制到captcha_platom目录下,然后运行tornado_server.py就行。
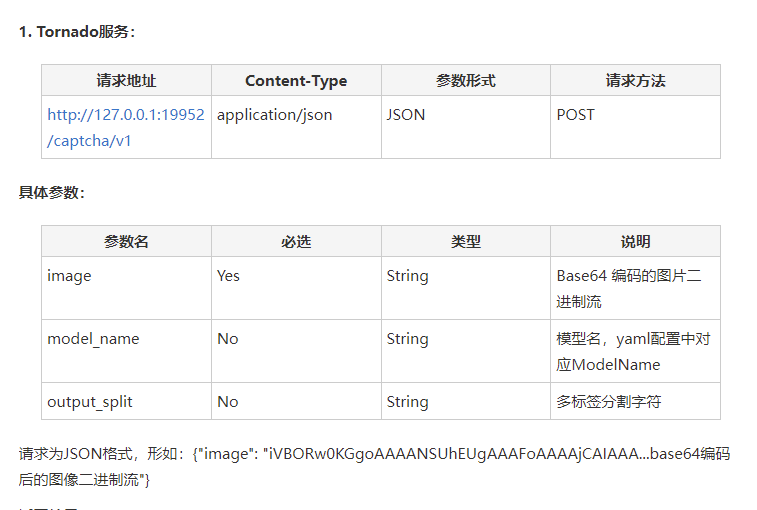
然后根据文档。运行tornado_server.py后会起一个API。地址为http://127.0.0.1:19952/captcha/v1,请求方式为application/json,具体参数查看作者的FreeBuf文章即可
我们试着调用一下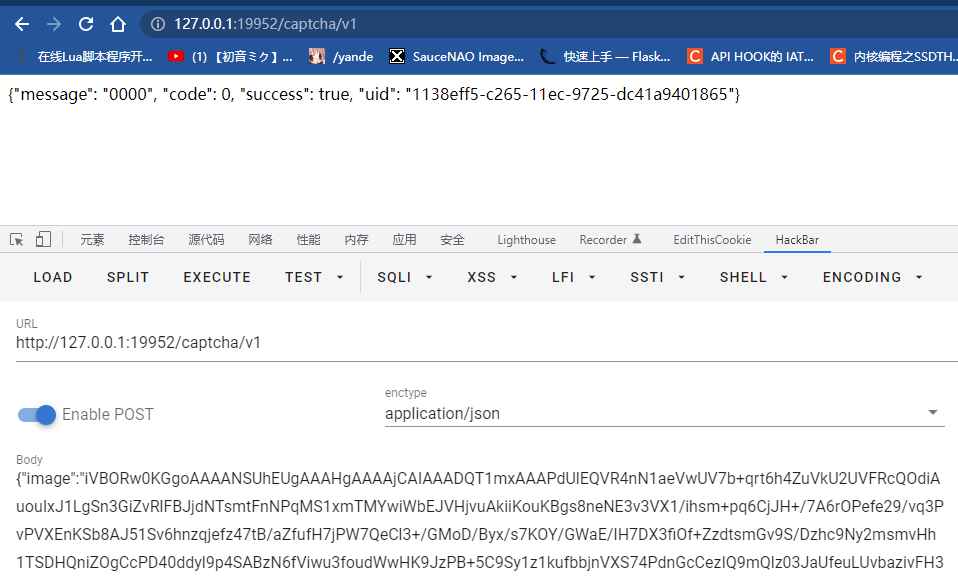
总体就大功告成辣。
通用化识别
以上我们就针对单一,开源,容易采集的项目进行了识别,但是对于那些闭源的目标来说,单纯用我们python生成的验证码跑识别成功率基本就没法看了。想要提高成功率,基本就是得对不同字体(包括与斜度),不同背景(花纹,纯色,甚至图片背景),不同扭曲程度(PS魔术棒!),不同噪点的验证码进行一个数据的生成然后在进行投喂。同时,传入参数的时候也比不能忘记把图片的分辨率来调整成我们训练时候的分辨率。来尽可能模仿目标。
结尾 & 后续
解决了验证码这个拦路虎,还有一个问题就是banIP了,下次看看怎么解决这个吧,估计会出一个云函数实践相关的,咕咕咕了。
让我无端联想起了一个13年至今的代验证验证码服务:2captcha
还是真人代识别,物美价廉,支持人民币支付宝付款🤣