
2022
摆烂了,直接上ELK了,简单粗暴快捷
前言
哪个男孩子不想拥有一条自己的裤子呢?
因为闲得无聊,所以也想整一个,正好看到盘里有以前老哥丢过来的各种东西
再加上学校的网速还算给力,于是就萌生了自己搭一个的念头。
二话不说,走起。
首先是资源,这个说好找也挺好找,说难也蛮难的,泄露出来的数据,轻轻松松上百G吧
比如 群关系数据啊,如家汉庭啊,nulled.io啊,前者90G,中间这个23G,后门那个13G,再加上什么各种QQ老密数据(9G左右),网易泄露的,以及soyun裤子流出(30G)左右。几百G倒还真的不难
现在的问题是,如何查询。
因为是自己用,所以性能要求不是非常高。但是在学校工作站部署了下soyun的裤子,虽然说内存只有4G是有限制,但是怎么说也是个E5-2603 v2啊,查询4e条数据一次竟然要9分钟= =
所以现在正在尝试解决方案。
数据处理
我第一个处理的是soyun社工库,网络上直接一个soyun.bak。
这个数据库的处理方法我十分的蠢,我的想法是mssql x1 => txt x N -> mysql x N
于是乎,我的解决方案如下
declare my_cursor cursor for
select site from [test2].[dbo].[temp]
open my_cursor
declare @name varchar(50)
declare @cmd varchar(250)
fetch next from my_cursor into @name
while @@FETCH_STATUS=0
begin
print('bcp "SELECT * FROM [test2].[dbo].[sgk] WHERE [site]='''+@name+'''" queryout "I:\'+@name+'_.txt" -c -S".\S2" -U"sa" -P"jikebianqiang"')
set @cmd = 'bcp "SELECT [name1],[pass],[email] FROM [test2].[dbo].[sgk] WHERE [site]='''+@name+'''" queryout "I:\'+@name+'_.txt" -c -S".\S2" -U"sa" -P"jikebianqiang"'
EXEC master..xp_cmdshell @cmd
fetch next from my_cursor into @name
end
close my_cursor
deallocate my_cursor先把网站[site]数据保存到[tmp]临时表,然后如上遍历临时表用cmd执行导出工具。
这样做能跑,但是有个很大的问题。。。
那就是,一次只能做一次查询,where一次只能输出一条结果到一个目标,然后从头跑一次。
这样做的后果呢。就是,库里有108个站点,然后完全读取一次数据库的时间需要9min。
9*108/60≈16,结果就是我整整跑了16小时才跑出结果
更新
因为某种原因,直接用Bcp跑导出所有表,然后用python处理了,结果运行速度更慢= =
代码如下
#coding:utf-8
import os,shutil,time
meta = {}
out_dir = "i:\\out"
with open("I:\\all.txt", 'r',encoding='gb18030',errors='ignore') as file:
while 1:
lines = file.readlines(100000)
if not lines:
break
for line in lines:
s = line.split("\t")
if len(s) != 4:
continue
#print(s)
t = s[3].strip().replace("\n","").encode("utf-8").decode()
o = None
if t == "":
t = "None"
if not os.path.isdir(os.path.join(out_dir,t)):
try:
os.mkdir(os.path.join(out_dir,t))
except Exception as e:
o = str(int(time.time()))
os.mkdir(os.path.join(out_dir,o))
if t not in meta:
if o != None:
out = open(os.path.join(out_dir,o,"0.txt"),"ab+")
else:
out = open(os.path.join(out_dir,t,"0.txt"),"ab+")
meta[t] = [0,0,out,o]
meta[t][1].write(("%s\t%s\t%s\n" % (s[0].strip(),s[1].strip(),s[2].strip())).encode("utf-8"))
meta[t][2] = meta[t][3]+1
if meta[t][4] >= 5000000:
meta[t][5].close()
if meta[t][6] != None:
meta[t][7] = open(os.path.join(out_dir,meta[t][8],str(meta[t][0])+".txt"),"ab+")
else:
meta[t][9] = open(os.path.join(out_dir,t,str(meta[t][0])+".txt"),"ab+")
meta[t][0] = meta[t][0] + 1
meta[t][10] = 0
#line = file.readline()总之八成是我的代码有问题,不过这样无所谓了。
先处理手头一些比较新的把,这个东西数据比较慢,就在后面慢慢跑吧。
库表设计
既然按照分表了,那么就不能单纯的 username,password,mail,phone,site这样一个表怼了。(soyun的就是这样直接储存4e数据的,震撼鳖鳖!
那么接下来就是设计如何分表。
我的设想是,按照不同的站区分成不同的库。然后根据数据量来。
比如一些小且杂的站点(比如自己脱的),都分在一个库。
目前主要麻烦的就是那些大公司的。比如腾讯网易等。
还有邮箱杂库等等。
这里我打算利用MERGE存储引擎来进行拆分设计。
详情可以参考这个:
之后接下来,就是数据重复的问题了。
使用mysql的LOAD
load data local infile "course.txt" into table course
fields terminated by ',' lines terminated by'\r\n';十分轻松的就导入了
更新x2
试着查询了一下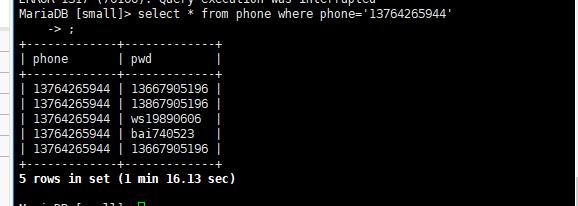
仅仅700w的数据,就需要1min16s,实在是太慢了
估计得想办法换成Nosql,我试试mongodb的水
更新x3
后来,设置了下索引,发现其实查询速度海星?
甚至查询速度比我笔记本本机都快。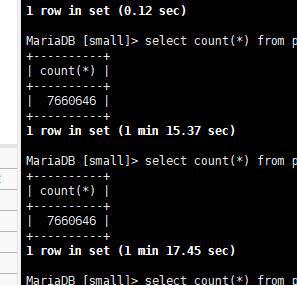
明明count()的速度比我本机慢好多好多。。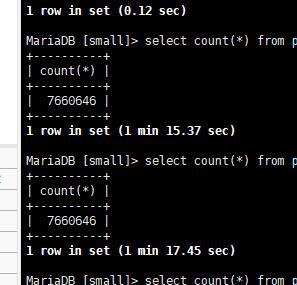
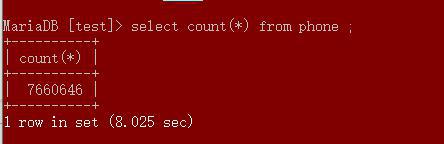
搞不懂了。
不过目前能搞清楚的是,裤子能继续用了,查询的速度在能接受的范围内。
2020-2-12更新
龟速导入了好久,然后终于再前几天导入的差不多啦。
基本7-8E左右的数据。
然后需要去重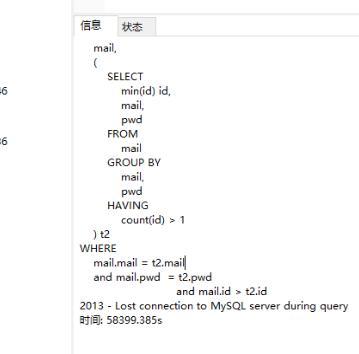
用了这个方法去重,连续500M的速度跑了11h之后,我当心我的SSD要炸了,于是就终止了。
放弃了去重的想法,将就用吧。
为啥700w要十多秒,我京东7200w数据 加上索引 毫秒可以跑完, 在nas上
另外, 有没有人数据互换呀, 优质整理好的数据, 都有索引外加python脚本查询
大概3-5亿级别
为啥不用ES呢?查询速度嘎嘎快
这裤子里只有账号和密码吧
能否分享一下,你懂的
大胸弟你是放自己电脑里嘛?感觉硬盘不够用啊,买服务器又贵
买外置机械啊,随便找个工程机当NAS,或者收一些二手盘
表哥文章挺新啊,巧了我也在整,思路,后端mysql分区分表,前端sphinx,杂七杂八的导入之前就先去重了,你那七百多万的汇总数,我开始还以为是某数字网站的呢,赶紧count了一下我的,发现还是有点差距。哈哈。
kibana+es 了解下
哇9BIE换主题啦
能否将库共享一下?
违法的,不能乱给_(:з)∠)_