前言
因为前两天打ctf时候遇到了一个题,挺有意思的。win10默认输入法会记录下词频和一些语句信息。
详细可以参考文章: 输入法取证:一种Windows8/10中文用户输入痕迹信息
文章地址很容易失效,我就提供标题了。
总之就是在C:\Users\username\AppData\Roaming\Microsoft\InputMethod\Chs 下有两个ChsPinyinUDL.dat和ChsPinyinIH.dat文件里面有记录词频信息。
依据上述基于数据流的逆向测试策略,对两个DAT用户词库文件进行结构分析,发现ChsPinyinlH和ChsPinyinUDL两个DAT文件存储的输入记录信息数据起始位置分别是在文件偏移地址0x1400处和0x2400处,每条用户输入记录信息的存储长度都是固定的,占用60个字节。
结构如下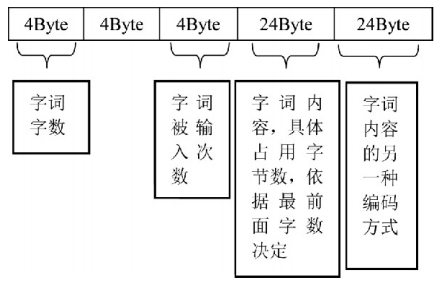
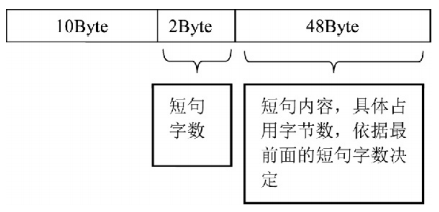
最后附上代码
f = open("ChsPinyinUDL.dat","rb")
data = f.read()
data = data[9216:]
f.close()
i = 60
n=1
while True:
chunk = n*i
chunk_len = data[chunk+12:chunk+12+48]
hex_chunk_len = ['%02x' % b for b in chunk_len]
print(chunk_len.decode("utf-16"))
n+=1
if chunk>=len(data):
break
f = open("ChsPinyinIH.dat","rb")
data = f.read()
data = data[5120:]
f.close()
i = 60
n=1
while True:
chunk = n*i
chunk_len = data[chunk:chunk+4]
hex_chunk_len = ['%02x' % b for b in chunk_len]
print(hex_chunk_len[::-1])
unicode_chunk = data[chunk+12:chunk+12+data[chunk]*2]
hex_unicode = ['%02x' % b for b in unicode_chunk]
print(hex_unicode[::-1])
print(unicode_chunk.decode("utf-16"))
n+=1
if chunk>=len(data):
break效果图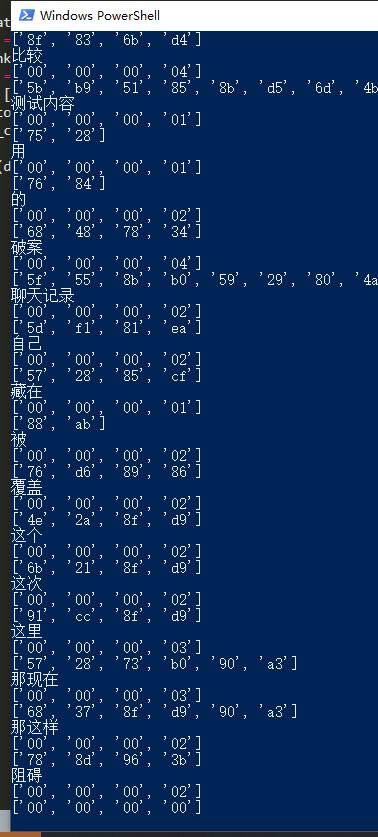
佬您好, 我最近在学习python, 想写一个词库互转的程序练练手, 请问您这段代码我可以参考后写进项目里吗?
ヾ(≧▽≦*)o
随便用